 번역 제공
번역 제공
김상욱 한양대 교수(컴퓨터소프트웨어학부) 연구팀이 최근 딥러닝 기술 성능을 기존 대비 약 2배 개선한 새로운 분산 딥러닝 기법 ‘알라딘(ALADDIN)’을 개발했다고, 한양대가 27일 전했다.
딥러닝은 수많은 계층으로 구성된 모델을 이용해 방대한 양의 빅데이터를 학습하는 기술로, 4차 산업혁명의 핵심기술로 평가받고 있다.
하지만, 딥러닝은 빅데이터 학습을 위해 방대한 시간과 자원이 필요했고, 이는 러닝 연구의 큰 걸림돌이 됐다. 이런 이유로 딥러닝 기술을 이용한 학습을 가속화하기 위한 연구들이 학계 및 산업계에서 활발하게 진행돼왔다.
김 교수팀이 개발한 ‘알라딘’은 분산 딥러닝 기술로, 수십·수백 대의 워커들로 구성된 분산 클러스터를 기반으로 딥러닝을 가속화하는 기법이다. 알라딘의 핵심은 기존 분산 딥러닝 기법들에 대한 면밀한 분석을 통해 분산 딥러닝에서의 성능저하 원인을 규명하고 이를 해결하는데 있다.
각 워커에서 개별 처리된 데이터는 파라미터 서버에서 전역 모델을 업데이트하는데 사용된다. 이때 각 워커는 자신이 처리한 데이터를 파라미터 서버에 전송하고, 파라미터 서버로부터 해당 데이터가 반영된 전역 모델을 수신한다. 즉, 워커와 파라미터는 한쪽이 일방적으로 데이터를 전송하는 비대칭적인 통신이 아니라, 서로 송신과 수신을 모두 수행하는 이른바 ‘대칭적 통신‘을 수행한다.
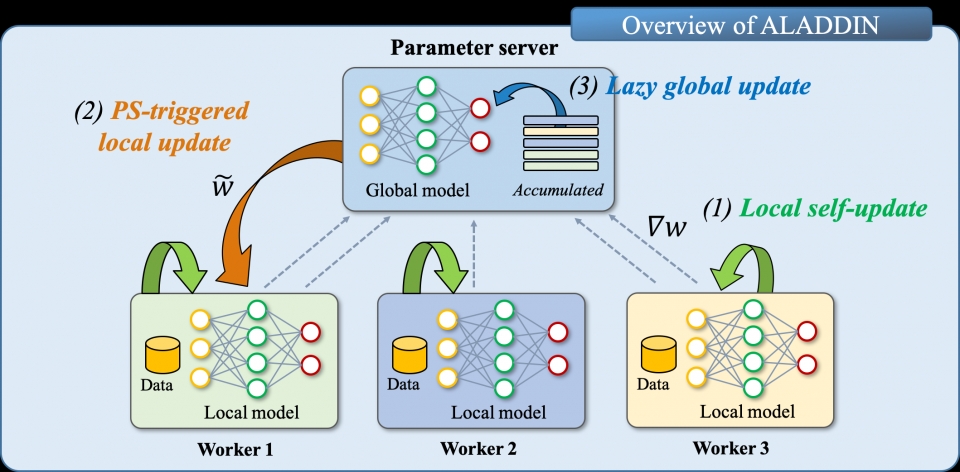
김 교수팀은 이러한 워커와 파라미터 서버 간 대칭적 통신이 분산 딥러닝의 성능저하를 유발하는 근본적 원인임을 밝히고, 이를 해결하고자 워커-파라미터 서버 간 비대칭 통신 기반 새로운 분산 딥러닝 방법론을 설계했다. 나아가 비대칭 통신으로 발생할 수 있는 정확도 성능 이슈를 해결하는 전략들도 함께 반영했다. 그 결과 알라딘은 기존 분산 딥 러닝 기법들과 비교해 정확도를 유지하면서도 최대 2배 가까이 성능이 개선됐다.
김 교수팀의 알라딘 연구는 지금까지 존재하는 딥러닝 기술뿐만 아니라 향후 개발될 미래 기술들에도 적용할 수 있다는 점에서 의의가 있다. 알라딘은 인공지능(AI) 분야의 다양한 영역에서 활용될 수 있는, 잠재력이 매우 큰 기술로 평가받을 전망이다.
한편, 김 교수팀의 연구는 두뇌한국(BrainKorea)21, 한국연구재단, 정보통신기획평가원의 지원을 받았으며, 고윤용 한양대 박사, 최기봉 한양대 연구원, 제현승 SK텔레콤 연구원, 그리고 이동원 미국 펜실베이니아 주립대 교수와 함께 진행했다.
알라딘은 그 기술의 독창성 및 우수성을 크게 인정받아 다음 달 1일부터 닷새간 개최되는 ‘The ACM International Conference on Information and Knowledge Management(이하 ’ACM CIKM‘) 2021’에서 발표될 예정이다. ACM CIKM은 세계적으로 인정받는 데이터 사이언스 분야의 탑 컨퍼런스 중 하나다.
윤정민 기자 lucas@kyosu.net
