 번역 제공
번역 제공카오스재단(이사장 이기형)이 인공지능(AI)을 주제로 2020 가을 카오스강연을 펼치고 있다. 지난달 7일부터 오는 12월 9일까지 매주 수요일 저녁 8시, 총 10회에 걸쳐 내로라하는 전문가들이 강연을 한다. ‘AI 크로스’를 주제로 의학, 기후, 음악, 수학, 로봇 공학 등 각 학문 분야에서 AI를 어떻게 최첨단으로 활용하고 있는지 살펴본다. 이번 8강에서는 신현정 아주대 교수(산업공학과)가 ‘바이오메디컬 인공지능’에 대해 강연했다.
카오스재단 ‘AI 크로스’ 강연 및 연재 순서
9 헬로 딥러닝: 직관적이고 명확하게 딥러닝을 이해하기
비둘기 병리학자 vs 인공지능 의사
폭증하는 의료데이터와 복잡한 유전체 정보
정밀의료, 신약개발… 바이오메디컬AI의 가능성
‘비둘기 병리학자’라고 불리는 실험이 있다. 리처드 레벤슨 컬럼비아대 교수가 2015년에 발표한 「유방암 방사선 이미지 관찰자로 교육시킬 수 있는 비둘기」 논문의 내용이다. 암 조직과 정상 조직을 찍은 엑스레이 사진이 비둘기에게 뒤섞여 주어진다. 이미지가 제시될 때마다 비둘기는 버튼을 쪼는 방식으로 반응한다. 악성이면 파란색, 정상이면 노란색을 쪼는 식이다. 정답을 맞히면 보상으로 먹이가 주어진다. 기초적인 학습 시스템이다.

비둘기의 성적이 놀랍다. 일주일을 훈련하면 90%대 정확도를 보이고 배율이 낮은 이미지에서도 약 2주가 지나면 85%대 정확도에 다다른다. 학습한 이미지가 아닌 새로운 조직 사진을 줘도 기존의 정확도와 비슷하게 분류해낸다. 무작위로 찍는 것이 아니라 시각 정보를 바탕으로 종양 이미지의 패턴을 학습하는 것이다. 여러 마리의 비둘기를 데리고 실험을 진행하면 통합 정확도는 99%에 근접한다. 반복을 통한 패턴 학습과 진단, 인공지능의 분별 원리와 같다. 다만 데이터가 덜 들고 학습 한계가 뚜렷하다.
“비둘기 의사와 인공지능 의사, 그리고 인간 의사 중 누구의 진단을 믿겠습니까” 신현정 아주대 교수(산업공학과)의 질문이다. 지난 25일 저녁 8시 온라인 생중계된 카오스재단 ‘AI크로스’ 여덟 번째 강연에서 신 교수는 의료 서비스와 유전체 공학을 잇는 인공지능 기술의 현 수준과 원리를 망라해 정리했다. 강연은 2부로 나뉘어 1부는 의료 서비스에, 2부는 질병과 유전자 데이터 분석에 각각 인공지능이 어떻게 응용되는지를 다뤘다.

급격하게 누적되는 의료데이터
인공지능과 기계학습이 의학 분야에 소환된 가장 현실적인 이유는 방대한 데이터다. 영상의 경우 CT, MRI 등 의료 이미지가 도합 20엑사바이트(Exabyte)에 달하는 것으로 추산된다. 영화 한 편을 2기가바이트라고 치면 약 100억 편에 해당하는 용량이다. 아울러 의료 이미지는 매년 20~40%씩 증가 중이다. “미국 병원만 해도 2005년부터 10년 사이 누적 데이터 용량이 열 배 늘어났다”라고 신 교수는 말한다.
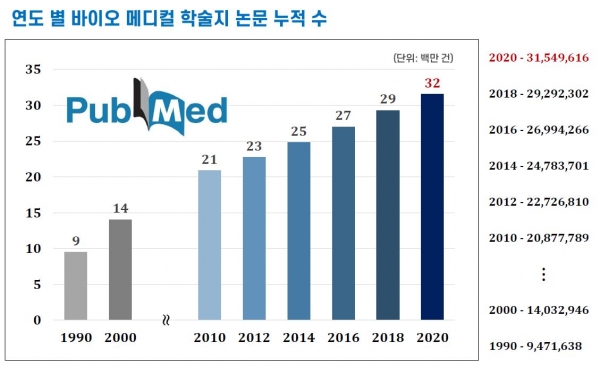
텍스트 데이터도 마찬가지다. 의학 서적부터 학술 논문, 환자 기록까지 무수한 비정형 데이터가 산적해 있다. 미국의 의학 및 생명공학 전자 라이브러리 ‘펍메드 센트럴(PubMed Central)’에 쌓여있는 논문만 약 3천100만 건에 달한다. 이 규모의 자료를 상시적으로 활용하고 응용하는 일은 인간의 힘만으로는 불가능에 가깝다. 막대한 데이터 풀은 기계학습을 위한 최적의 조건이기도 하다. 한계와 수요가 만나 의료 인공지능을 불러들인다.
이쪽에서 가장 유명한 인공지능 의사는 IBM의 왓슨이다. 왓슨은 개발 초기 미국의 MSK 암센터가 보유한 각종 학술지와 교과서, 임상시험 자료를 학습하고 모의실전을 거친 뒤 실용화됐다. 다만 아직 미완의 프로젝트다. 암 진단 및 치료 방법 제시에 있어 미국에서는 인간 의사와 90%대의 의견 일치율을 보였지만 인도와 한국에서는 절반 이하로 떨어졌다. 인종, 문화, 의료보험 체계 등 지역적 요소가 반영되지 못한 탓이다. 한국에서는 이 부분을 개량한 ‘닥터 앤서(Dr. ANSWER)’가 2018년부터 개발 중이다.
질병과 유전자를 잇는 피라미드 네트워크
의학 데이터 분석은 생명 공학으로 이어진다. “요즘 의사들은 임상만 하면 안 되고 유전자까지 공부해야 한다”라고 신 교수는 말한다. 의료 인공지능에 바이오 인공지능을 결합한 정밀의료 때문이다. 정밀의료는 앞서 ‘AI크로스 ‘ 3강에서도 다뤄진 바 있다. 인간의 생명을 구성하는 유전 정보와 각종 질병 사이 복잡한 관계망을 해석해 개인별 맞춤 치료 방식을 제공하고자 하는 프로젝트다.
이를 위해 신 교수는 ‘바이오메디슨 피라미드(BioMedicine Pyramid)’라는 개념을 고안했다. 제일 아래층의 유전체 네트워크부터 전사체와 단백질 구조, 대사경로, 질병과 약물을 거쳐 인간에 이르는 관계망을 수직적으로 도식화한 것이다. 2007년 앨버트-라슬로 바라바시 교수가 발표한 ‘인간 질병 네트워크’에서 영감을 얻었다. 질병 간 연관성과 특성을 분류하고, 이것을 유전체까지 확대해 어떤 DNA가 어떤 질병과 연관되는지 섬세하게 추적하고자 하는 모델이다.

신약 개발 효율 높이는 AI
피라미드 네트워크의 전반을 파악하기 위한 계산 양은 얼마나 될까. 의학주제표목(MeSH)에 따른 질병 수가 약 5천 개이고 인간의 유전자는 2만3천여 개로 알려져 있다. 질병과 질병 사이 관계를 계산하면 5천 곱하기 5천인데 여기에 유전자와의 관계까지 포함하면 2만을 더 곱한다. 결과적으로 약 5천억 번의 연산이 필요한 셈이다. 신 교수는 “사람이 하기 어려운 계산양이다. 이런 부분에 기계학습을 적용해 계산하고 표현할 수 있다”라고 부연한다.
관건은 효율과 단축이다. “약물 개발에는 후보 물질 선정부터 신약 개발까지 15년 정도가 걸리고 예산은 약 1조원을 잡아야 한다. 그런데 성공률은 0.01%밖에 안 된다.” 신 교수의 설명이다. 이 과정에 질병과 유전자 사이, 유전자와 유전자 사이 관계에 대한 인공지능의 분석을 적용하면 질병의 실체를 파악하는 과정을 단축할 수 있다. 실제 존슨앤존슨, 로체, 바이어, 화이자 등 거대 글로벌 제약회사 대부분이 AI 회사를 인수하거나 파트너십을 체결해 관련 연구에 투자하고 있다.
이 외에도 AI 간호사와 AI 심리치료사 AI 정신 분열증 환자 사이 대화, 인공지능을 통한 치매 원인 유전자 추적 연구, 의료 데이터의 개인 정보 보호 문제 등이 거론됐다.
박강수 기자 pps@kyosu.net
