 번역 제공
번역 제공- 국제학술대회 ‘ACM CIKM 2020’에서 23일 발표 예정
- 예측정확도와 훈련 속도는 각각 최대 21% 및 59% 향상돼
최근 들어 인공지능 기술의 눈부신 발전과 빅데이터 양의 증가로 인해 심층 학습(딥러닝, deep learning)이 다양한 데이터 분석 응용에서 활용되고 있다. 심층 학습의 핵심 기술은 주어진 훈련 데이터로부터 예측정확도를 최대화한 모델을 빠르게 구축하는 것이다.
KAIST(총장 신성철)는 전산학부 이재길 교수 연구팀이 심층 학습 모델의 예측정확도와 훈련 속도가 대폭 향상된 새로운 모델 학습 기술을 개발했다고 20일 밝혔다.
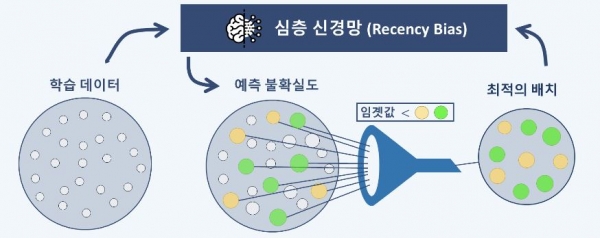
심층 학습 모델을 학습하는 과정은 반복적으로 모델의 매개변수를 최적화하는 단계로 이뤄진다. 반복마다 훈련 데이터로부터 일부(예: 32개) 데이터를 선정해 최적화에 사용하는데 이때 선정된 데이터 샘플을 배치(batch)라 부른다. 무작위로 배치를 선택하면 최고의 정확도가 항상 보장되지 않기 때문에 이런 문제점을 개선하기 위해 최근 인공지능 학계에서는 더 나은 배치 선택 방법에 관한 연구가 활발히 진행되고 있다.
이재길 교수 연구팀이 개발한 기술은 심층 학습 모델의 학습 진행 상황에 맞게 최적의 배치를 구성하도록 하는 기술이다. KAIST 지식서비스공학대학원에 재학 중인 송환준 박사과정 학생이 제1 저자로, 김민석 박사과정 학생과 김선동 박사가 각각 제2, 제3 저자로 각각 참여했다.
이번 연구 결과는 데이터 처리 및 분석 분야의 국제 저명학술대회인‘국제컴퓨터학회 정보지식관리 콘퍼런스(ACM CIKM: Association of Computer Machinery International Conference on Information and Knowledge Management) 2020’에서 23일 발표된다. (논문명 : Carpe Diem, Seize the Samples Uncertain "at the Moment" for Adaptive Batch Selection)
배치 선택에서는 현재 모델 학습 단계에 가장 도움이 되는 데이터를 효과적으로 선택해야 한다. 도움이 될지를 판단하기 위해 이재길 교수팀이 개발한 방법은 해당 데이터에 대한 이전 추론 결과를 활용한다.
단계별 추론단계에서 결과가 매우 일관적일 경우, 해당 데이터가 너무 쉬어 계속 맞추거나 반대로 너무 어려워 전혀 맞추지 못한다고 볼 수 있다. 다시 말하자면 이러한 데이터는 결코 도움이 되지 않는 데이터라 할 수 있다. 반대로 최근 몇 단계에서의 추론 결과가 그다지 일관적이지 않다면 해당 데이터에 대한 추론이 혼동되고 있다는 뜻이므로 현재 시점에서 꼭 필요한 데이터이다.
논문 제목에 있는 `카르페 디엠(Carpe diem)'은 호라티우스의 라틴어 시 한 구절로부터 유래했고 영화 `죽은 시인의 사회'에서 인용돼 유명해졌다. 보통 `현재를 잡아라(Seize the day)'로 번역되는데 가장 최근 몇 단계인 현재의 추론 결과가 불확실한 데이터를 선택하도록 설계된 제안 방법론의 철학을 잘 설명한다고 판단해 연구팀은 논문 제목에 이를 이용했다.
연구팀은 새로 개발한 배치 선택 방법론을 `최신 편향(Recency Bias)'이라고 이름을 붙이고 이미지 데이터에 널리 활용되는 다양한 합성 곱 신경망(CNN)의 학습에 적용했다. 그 결과, 기존 방법론 대비, 예측정확도(이미지 분류 문제)에서 최대 21% 오류를 감소시키는 한편 훈련 속도(심층 신경망 미세 조정 문제)에서는 최대 59% 시간을 단축했다.
제1 저자인 송환준 박사과정 학생은 "이번 연구는 심층 학습의 핵심 기술ˮ 이라면서 "다양한 심층 신경망에 폭넓게 적용할 수 있어 심층 학습의 전반적인 성능 개선에 기여할 것ˮ이라고 밝혔다.
연구팀을 지도한 이재길 교수도 "이 기술이 텐서플로우(TensorFlow) 혹은 파이토치(PyTorch)와 같은 기존의 심층 학습 라이브러리에 추가되면 기계 학습 및 심층 학습 학계에 큰 파급효과를 낼 수 있다ˮ고 기대했다.
한편, 이 기술은 과학기술정보통신부 재원으로 정보통신기획평가원의 지원을 받아 SW컴퓨팅산업원천기술개발사업 SW스타랩 과제로 개발한 연구성과 결과물(2020-0-00862, DB4DL: 딥러닝 지원 고사용성 및 고성능 분산 인메모리 DBMS 개발)이다.
